
Soul App burst onto the social networking scene in 2016 and since then it has managed to capture the attention and loyalty of China’s Gen Z. While the unique concept of the social networking platform has undoubtedly been its ace card, the early adoption of AI by the CEO of Soul, Zhang Lu has also contributed significantly to the app’s meteoric rise.
From a text-based system that allowed users to discover each other on the basis of mutual interests to a full-fledged AI-driven social networking platform, that app’s evolution can be credited to Soul Zhang Lu’s openness to embracing everything that AI technology had to offer.
The engineering team of the social networking app started its journey into the world of artificial intelligence with the home-developed LingXi engine. Through it, Soul’s team introduced an AI-powered matchmaking algorithm into social networking.
By 2020, Soul Zhang Lu’s engineers had expanded their reach into AI-generated content (AIGC). This brought intelligent chatbots, voice synthesis, and 3D avatars to the platform. In 2023, the Soul team launched its namesake model, Soul X. A proprietary creation, Soul X was capable of multilingual voice interaction, AI-generated music, and speech synthesis.
Within a year of Soul X’s introduction, the platform’s engineers were ready to up their game with their research on multimodal emotion recognition. This was presented at ACM MM 2024. And now, 2025 is turning out to be just as monumental a year.
A few days ago, Soul Zhang Lu’s team submitted a research paper titled “Teller: Real-Time Streaming Audio-Driven Portrait Animation with Autoregressive Motion Generation” for presentation at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2025.
The Conference is known for its extremely rigorous selection process. The paper submitted by the social networking app’s team was one among the more than 13,000 entries received by CVPR’s selection panel. Soul’s research made it to the final list of approximately 2600 submissions.
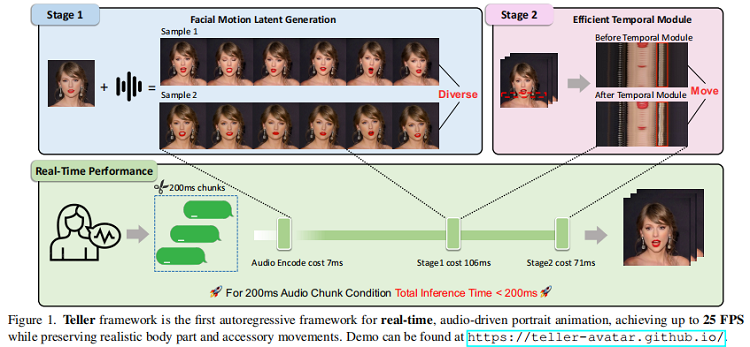
In the technical paper, Soul Zhang Lu’s engineers proposed a unique autoregressive framework for real-time audio-driven portrait animation (Talking Head). While the framework is based on a diffusion model, it uses one-step diffusion, which sets it apart from traditional video generation models.
Through their research, the AI experts at Soul endeavored to not just address the industry challenge of time-consuming video generation but also enhance the naturalness and realism of head and body movements during speech.
Soul Zhang Lu’s team started by deconstructing the key steps of diffusion-based models. Then, these steps were restructured by using LLMs (large language models) and one-step diffusion techniques. The goal was to further hone Soul X’s multimodal capabilities, allowing it to simultaneously generate text, speech, and video. In the paper, the research team segregated the Talking Head task into two modules:
- FMLG (Facial Motion Latent Generation): This uses an autoregressive language model that combines the power of large-scale learning and efficient diversity sampling. Together, these yield accurate and varied facial motion generation.
- ETM (Efficient Temporal Module): This employs one-step diffusion in a bid to create realistic body muscle and accessory movements.
When pitched against traditional diffusion models, Soul Zhang Lu’s Talking Head model offered notable improvement in video generation efficiency along with superior performance in micro-movements, facial-body coordination, and naturalness.
What makes this research revolutionary is the fact that unlike traditional models, Soul’s “Talking Head” model does not require significant processing time nor does it struggle with natural motion. The AI avatars generated by regular models often come across as stiff and unrealistic because they just have a few facial expressions at their disposal.
In contrast, the research presented by Soul Zhang Lu’s team can be used to generate Talking Heads capable of smooth, dynamic, varied, and natural expressions. And, they offer precise lip syncing to boot. The best part is that this model achieves these effects without being computationally demanding.
In simple words, through this research, Soul’s team has managed to steer its AI capabilities toward meeting the growing demand for more expressive and interactive AI-driven avatars. Soul App’s CTO Tao Ming stated in a recent interview that face-to-face interactions still beat all other forms of communication when it comes to exchanging information and deriving emotional gratification from the interaction.
Hence, Tao Ming surmised that in order to be effective, AI-driven digital interaction would need to follow the same principle. So, it won’t be surprising to see the actual implementation of the Talking Head model into the platform’s many features sooner than later.
Undoubtedly, having their research showcased at CVPR 2025 is a major milestone for Soul Zhang Lu’s team. But what will be even more exciting to see is how the new framework transforms the way in which the platform’s users engage with virtual persons.
The work done thus far by Soul team clearly indicates that the platform’s engineers are reaching for a future where AI-powered communication will be indistinguishable from real-life social interactions.
Will Soul Zhang Lu’s team achieve this lofty goal? Only time will tell. But for now, they sure seem to be headed in the right direction.